Saturday, 7 September 2024
Naive Bayes
Suppose you are a product manager, you want to classify customer reviews in positive and negative classes. Or As a loan manager, you want to identify which loan applicants are safe or risky? As a healthcare analyst, you want to predict which patients can suffer from diabetes disease. All the examples have the same kind of problem to classify reviews, loan applicants, and patients.
Naive Bayes is the most straightforward and fast classification algorithm, which is suitable for a large chunk of data. Naive Bayes classifier is successfully used in various applications such as spam filtering, text classification, sentiment analysis, and recommender systems. It uses Bayes theorem of probability for prediction of unknown class.
Naive Bayes is a statistical classification technique based on Bayes Theorem. It is one of the simplest supervised learning algorithms. Naive Bayes classifier is the fast, accurate and reliable algorithm. Naive Bayes classifiers have high accuracy and speed on large datasets.
Naive Bayes classifier assumes that the effect of a particular feature in a class is independent of other features. For example, a loan applicant is desirable or not depending on his/her income, previous loan and transaction history, age, and location. Even if these features are interdependent, these features are still considered independently. This assumption simplifies computation, and that's why it is considered as naive. This assumption is called class conditional independence.
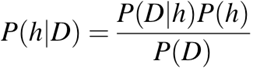
- P(h): the probability of hypothesis h being true (regardless of the data). This is known as the prior probability of h.
- P(D): the probability of the data (regardless of the hypothesis). This is known as the prior probability.
- P(h|D): the probability of hypothesis h given the data D. This is known as posterior probability.
- P(D|h): the probability of data d given that the hypothesis h was true. This is known as posterior probability.
Example: To get the probability of Diamond Queen, the above formulae could be substituted as below:

Source: https://www.youtube.com/watch?v=PPeaRc-r1OI&list=PLeo1K3hjS3us_ELKYSj_Fth2tIEkdKXvV&index=54
K Means Clustering Algorithm
This is useful to know as k-means clustering is a popular clustering algorithm that does a good job of grouping spherical data together into distinct groups. This is very valuable as both an analysis tool when the groupings of rows of data are unclear or as a feature-engineering step for improving supervised learning models.
Clustering models aim to group data into distinct “clusters” or groups. This can both serve as an interesting view in an analysis, or can serve as a feature in a supervised learning algorithm.
Consider a social setting where there are groups of people having discussions in different circles around a room. When you first look at the room, you just see a group of people. You could mentally start placing points in the center of each group of people and name that point as a unique identifier. You would then be able to refer to each group by a unique name to describe them. This is essentially what k-means clustering does with data.

How to determine K i.e number of Clusters
Here the below case has K as 2 and the below diagram shows the Sum of Squared Errors of each point to it's centroid.


Source: https://www.youtube.com/watch?v=EItlUEPCIzM&list=PLeo1K3hjS3us_ELKYSj_Fth2tIEkdKXvV&index=53
https://www.datacamp.com/tutorial/k-means-clustering-python
K Fold Cross Validation
Imagine you are training a machine learning model, but you are not sure how it will perform on new, unseen data. That is where K-Fold Cross-Validation comes in. It offers a sneak peek at how your model might fare in the real world. This technique helps make sure that your predictions are not just a one-hit wonder but consistently reliable across new, unseen datasets.
K-Fold Cross-Validation is a robust technique used to evaluate the performance of machine learning models. It helps ensure that the model generalizes well to unseen data by using different portions of the dataset for training and testing in multiple iterations.

Random Forest
Random forests are a popular supervised machine learning algorithm.
- Random forests are for supervised machine learning, where there is a labeled target variable.
- Random forests can be used for solving regression (numeric target variable) and classification (categorical target variable) problems.
- Random forests are an ensemble method, meaning they combine predictions from other models.
- Each of the smaller models in the random forest ensemble is a decision tree.

Source: https://www.youtube.com/watch?v=ok2s1vV9XW0&list=PLeo1K3hjS3us_ELKYSj_Fth2tIEkdKXvV&index=51
https://www.datacamp.com/tutorial/random-forests-classifier-python
Decision Tree
A decision tree is a flowchart-like tree structure where an internal node represents a feature(or attribute), the branch represents a decision rule, and each leaf node represents the outcome.
The topmost node in a decision tree is known as the root node. It learns to partition on the basis of the attribute value. It partitions the tree in a recursive manner called recursive partitioning. This flowchart-like structure helps you in decision-making. It's visualization like a flowchart diagram which easily mimics the human level thinking. That is why decision trees are easy to understand and interpret.

Source: https://www.youtube.com/watch?v=PHxYNGo8NcI&list=PLeo1K3hjS3us_ELKYSj_Fth2tIEkdKXvV&index=49
https://www.datacamp.com/tutorial/decision-tree-classification-python
Code: https://github.com/LeelaPrasadG/AILearning/tree/main/ML/5_DecisionTree
Subscribe to:
Posts (Atom)
-
Source: https://harshal-soni.medium.com/onehotencoding-vs-labelencoder-vs-pandas-get-dummies-how-and-why-b190dff7a86f https://stackoverfl...
-
Linear regression analysis is used to predict the value of a variable based on the value of another variable. The variable you want to pre...
-
This is useful to know as k-means clustering is a popular clustering algorithm that does a good job of grouping spherical data together in...
